
We recently purchased Sitecore Search and today was my first chance to have a look at the product in detail and to try and get it working. I thought I would share my initial experiences after the first 24 hours playing around with it and also my first attempt at building a user interface to consume the new APIs.
The UI deals with all the examples shown in the Sitecore documentation - Integrate with RestAPIs:
- Initialize a page with some search results and show all available facets
- Update the results based on a search term
- Update the results based on a selected facet
- Sort the results by a property (ascending or descending)
- Populate the search bar using suggestions from API based on characters entered
You can fin the code on my Github page here: https://github.com/deanobrien/sitecore-search
My experience
My first contact with ‘Sitecore Search’ was when I received an email from ‘no-reply@reflektion.com’ inviting me to join ‘Sitecore Discover Customer Engagement Console’. Think this could probably do with an update to mention the product we purchased? Or are Sitecore search and discover one and the same?
Getting Started
After creating an account and having a quick peek at the tools that were on offer, we decided to make a start and headed over to the online docs: https://doc.sitecore.com/search/en/developers/search-developer-guide/getting-started-with-sitecore-search.html
As you navigate around the Customer Engagement Console (CEC), you will notice some of the sections have TODO or TODO (OPTIONAL) showing, which was a useful pointer to begin with. One of the things you need to do first is to select an Attribute Template, which you should set to Generic Vertical Spec For Content.
If you are following the walkthrough included in the getting started documentation, you then need to add the keywords attribute and make a few more configuration selections. This all seemed very straight forward, until I started getting an error when saving the new attribute ‘The product attributes are not properly defined’. This magically disappeared after renaming the attribute a couple of times then resaving… not sure what happened there.
Once you have completed all the TODOs in the Domain Settings area, you should notice a new menu item for “Sources” (icon of a plug) appears in the left menu.
Configure sources
Basic Crawler with XPath Crawler
You begin by adding a simple web crawler, give it Request trigger which is essentially the entry point for the crawler, then specify settings like how many layers deep to crawl, max items and scan frequency etc. Finally you need to setup attribute extraction using xPath queries (see below). With that in place you can publish the source and it will automatically be queued to start crawling.
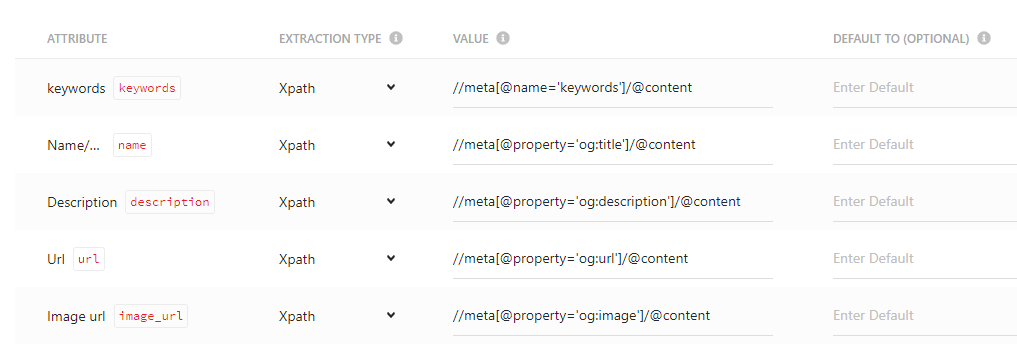
If all goes well, you will see ‘Finished’ next to your source when you go to sources page. But if its anything like my experience you will see ‘Failed’. If this is the case, click into the source and you will see a red message at the top of the screen showing how many errors were encountered. Hover over this and it will show you some details of the first 1 or 2 errors… I would much have preferred to see all the errors, but maybe I am missing something…
Our errors were pretty easy to fix. The crawler had decided to leave our domain and start looking at social sites etc, so this was quickly rectified by adding some exclusion patterns. A glob expression like this: **linkedin** will keep it from straying in that direction. I appreciate the advanced crawler has more control over things like ‘allowed domains’, but I would have appreciated a tick box or something on the simple crawler to say ‘Do not leave the source domain’. This would have saved me adding loads of exclusions.
With those final tweaks in place, I set the crawler going again and was glad to see that it finally finished without error. You can confirm this by jumping over to the content area and browsing to see if your content is coming in as you would expect it.
One thing I noticed was that we were getting some duplicate URLs showing in our content store, which I believe is down to some the pages on our site having funky masked redirects on them… To over come this, I tried switching over to use a sitemap trigger (as our sitemap has no duplicates). However, I was not able to get the source to successfully crawl, no matter how I played with the settings. Every time, I got an error saying only 0 documents had been crawled. I thought it might be due to the attribute extractor not being able to get ‘required’ fields – but we were using the same settings from the previous successful attempt.
I think a useful feature would be to add some kind of “test this connection” button, which attempts to get the first document from the trigger and reports back any issues blocking it.
Basic Crawler with JS Extractor
I then wanted to add a second source, so that any testing in the future would have a variety of ‘Content Types’ to fetch and facet over. With this in mind, I created a new basic crawler to target our Youtube channel. However, this time instead of an xPath, I opted to use a JS extractor which you can see below:
function extract(request, response) {
$ = response.body;
return [{
'description': $('meta[name="description"]').attr('content') || $('meta[property="og:description"]').attr('content') || $('p').text(),
'name': $('meta[name="title"]').attr('content'),
'type': 'video',
'url': $('meta[property="og:url"]').attr('content'),
'image': $('meta[property="og:image"]').attr('content')
}];
}I also needed to add a matcher glob expression with exprerssion **watch**, which narrowed down the crawler to only attempt to index video pages. After saving and publishing this, I was glad to see 30 videos had been indexed. There were a lot more video available, but finding them in realtime requires you to scroll – so im guessing some adjustments need to be made to get the rest… but for the time being, I have some more content so I was happy.
Verifying your source configuration
This is the next step in the walk through. You need to confirm that the crawler has found and indexed data. You do this by first checking you can see documents in the content collection (3 part cylinder icon in left menu), then by checking you can access that data via the API.
To confirm API access, the documentation recommends using the API explorer. The guidance and the explorer refer to terms like Pages, Widgets and URI. Given that I was following a ‘Getting Started’ walk through and none of these features had been introduced, it wasn’t immediately obvious what values needed adding at this point – I had no idea (and still don’t) what to add for the ‘Url of the current page’.
Configuring Search Features
This the final of the three walkthroughs is fairly simple and straight forward to follow. It looks in more detail at features such as Textual Reference, Suggestions and Sorting. With this you can start to gain a clearer idea of the types of functionality that is available and that these features actually constitute widgets, that can be configured and called upon via the search API. My understanding (well a guess really) is that groups of widgets can then be added to pages and each page (and widgets within) can be assigned rules and variations. Thus by calling different pages, you access different versions of similar widgets?
Integrating Using Rest APIs
At the bottom of the final walkthrough is a link to a page to Integrate using rest APIs. https://doc.sitecore.com/search/en/developers/search-developer-guide/integrating-using-rest-apis.html Its on this page that the penny starts to drop and I got a much clearer idea of how a potential solution might hang together. How you might make multiple calls from within one page / application, in order to do things like:
- Initialize a page with some search results and show all available facets
- Update the results based on a search term
- Update the results based on a selected facet
- Sort the results by a property (ascending or descending)
- Populate the search bar using suggestions from API based on characters entered
The API explorer comes in useful at this point to just paste in queries (from the above page) and test responses.
Building a Test UI
When building a user interface to consume and test the APIs, the recommendation from the Sitecore representative that helped with our onboarding was to use a React SDK. However, I have yet to master the React Framework (a challenge for another day). So I set about writing a simple twitter bootstrap page that uses JQuery to call the Search APIs. After not too much playing about, I was able to create something that dealt with all the examples that are mentioned in the ‘Integrating using rest APIs’ page.
Summary
My experiences with Sitecore Search have on the whole been very positive. With a couple of basic web crawlers, I was able to get enough data into the index to be able to start being able to start delivering a search experience. We still need to work out how to get the sitemap trigger functioning correctly, and also had some difficulty getting the advanced crawler to access gated content. But im sure with support from Sitecore we will overcome those issues. It may well be that we need to consider another approach using for example the ingestion API.
Building the UI was fairly straightforward I was able to build a pretty basic search experience in a few hours, but it would have been nice to have been provided a better more refined example. I appreciate that Sitecore have put some effort into providing a React SDK, which is most likely a much faster streamlined approach to consuming the APIs and more relevant in the new headless world they are steering toward. But it would be a nice touch in the future if they could provide some similar support to integrating with good old fashioned MVC, CSHTML views and JQuery.